So, nachdem ich die letzte Woche mit "Voraussetzungen aufbauen" verbracht habe, und wegen Zeitmangel am Wochenende sogar einen vorbereiteten Füller-Artikel posten musste, kommen wir heute (endlich) zu dem, was ich eigentlich mit Euch diskutieren wollte. Zu diesem Artikel sind mir Eure Kommentare besonders wichtig; ich weiß aber, dass es nach dem Absenden eines Kommentars im Browser einen Timeout hagelt. Das ändert aber nichts dran, dass der Kommentar ordentlich gepostet wurde.
Heute soll es nun endlich darum gehen, wie man Konfigurationsarbeiten ermöglicht und unterstützt, bei denen sich derjenige, der die Arbeiten ausführt, aktiv auf den zu bearbeitenden Systemen einlogged. Dabei schließe ich ausdrücklich das manuelle Arbeiten mit ssh oder mehrfach-ssh wie mssh und cssh ein, meine aber auch semiautomatisierte Arbeiten wie xargs --max-procs oder parallel(1) bis hin zum vollautomatischen Prozess, z.B. mit Ansible.
Continue reading "Privilege Escalation für Konfigurationsmanagement, Teil II"
Auf meinen Systemen bin ich im wesentlichen der einzige Shell-Benutzer. Die hier vorgeschlagenen Methoden können natürlich auch auf eine größere Menge von Accounts angewendet werden, wobei ab einer gewissen Grenze manche Verfahren nicht mehr skalieren.
lokaler Login
Lokaler Login auf der Konsole ist bei meiner Arbeitsweise die Ausnahme. Das passiert im Wesentlichen nur bei Störungen, wenn Netz und/oder ssh nicht mehr funktionieren. Die bei weitem häufigste Methode des Zugriffs auf die Shell erfolgt via ssh über das Netz. Da ich auf meinen Systemen natürlich sudo-berechtigt bin, benötige ich das zum Account gehörende Passwort (außer zum Konsolen-Login im Störungsfall) nur, um mich bei sudo zu authentifizieren um root werden zu können.
Continue reading "Meine Best Practice für Shell-Accounts und ihre Absicherung (mit ssh)"
Es war vor einigen Jahren, auf einem Treffen der SAGE Karlsruhe, wo im Rahmen eines Lightning Talks ssh proxycommand vorgestellt wurde. Ich hatte mich bisher immer mit einzelnen ssh-Aufrufen von Host zu Host weitergehangelt, und ssh proxycommand war für mich damals der erste Weg, direkt mit einem "natürlich" erscheindenen ssh-Aufruf trotz Sprunghost-Zwang auf dem Zielsystemen zu landen.
Das Verfahren wurde in neueren OpenSSH-Versionen noch zweimal vereinfacht, und in diesem Artikel möchte ich die Unterschiede herausstellen.
Continue reading "ssh proxycommand, ssh -W, ssh proxyjump"
Wenn man sich die Konfiguration seiner Systeme (managed systems) von einem Automaten (Konfigurationsmanagement-System, KMS) abnehmen lassen möchte, muss man ihm dazu die notwendigen Rechte geben. Da beißt die Maus keinen Faden ab.
Aber was sind die notwendigen Rechte, wie gibt man sie dem Automaten, und welche Implikationen für die Systemsicherheit (im Sinne von security) haben sie?
In diesem Artikel und seinen weiteren Teilen stelle ich ein paar Methoden vor, versuche ihre Vor- und Nachteile herauszuarbeiten und bitte euch um Kommentare und eure Meinung dazu. Dieser Teil 1 beschäftigt sich mit dem, dem ich eigentlich nur einen Absatz widmen wollte, und aus dem dann ein eigener Artikel geworden ist: Dem Pull-Prinzip mit einem Agenten.
Continue reading "Privilege Escalation für Konfigurationsmanagement, Teil I"
Linux Weekly News hat vor ein paar Jahren eine Artikelreihe über Namespaces im Linux-Kernel veröffentlicht. Inzwischen gibt es da zwar eine gewisse Überdeckung zu den Manpages (z.B. man 7 namespaces), aber etwas ausführlicher ist LWN dennoch. Ich verblogge das hier, damit ich nicht immer wieder suchen muss.
Und ja, ich bin noch da. Im Moment leider wieder etwas seltener, da ich aufgrund familärer Verpflichtungen höchster Wichtigkeit tausende von Kilometern im ICE herunterreißen muss.
git is an unbelievably powerful tool which is unfortunately rather picky in choosing its friends. Documentation is available in copious amounts and this blog article adds to the mountain.
Unfortunately, the documentation out there always assumes the ideal case: A small project, a handful of colleagues who are motivated and doing the right thing, a workflow agreement that matches the work to be done and no mistakes. Reality is different, and so you might find yourself wedged in broken workflows, surrounded by unwilling or incompetent cow-orkers and/or a git repository that has grown historically and still is carrying the burden of misguided work of decades.
In this blog article, I'd like to introduce you to my way of trying things with git. It allows you to easily do things in the right and in the wrong way while immediately seeing the results of your actions. Let me know whether it's of any help for you to grok git (which I have not fully managed yet).
Continue reading "git workflow trial environment"
I have just uploaded PowerDNS 3.3-1~exp1 to Debian experimental. This new upstream version has introduced its own include directive, so Debian was able to drop its patch. Hence, our conffiles had to grow a .conf extension, which most of them didn't have in previous version.
If anybody wants to test updates from PowerDNS 3.1 to the new 3.3-1~exp1 in Debian unstable, please go ahead and report bugs in the Debian BTS. The package is known to not offer seamless DNSSEC, I'll work on that before I upload to unstable.
While we're at it: I would appreciate help with the PostgreSQL backend. Myself, I use mainly MySQL and am not too proficient in PostgreSQL. I'll accept both patches and more formal co-maintenance.
Migrating a Debian installation between architectures has always been difficult. The recommended way to "crossgrade" an i386 Debian to amd64 Debian is to reinstall the system, move over data and configuration. For the more brave, in-place crossgrades usually involved chroots, rescue CDs, a lot of ar p | tar xf - data.tar.gz and luck.
I have never been brave when it comes to system administration, have done a lot of architecture migrations with reinstallation, and have always taken the opportunity to clear out the contamination that accumulates itself when a system is running for a long time. I would even recommend doing this to most people even now. However, I have a few very ugly systems in place that are still on i386 because I didn't dare going the reinstallation path.
Doing in-place crossgrades has become a lot easier since wheezy's release, since once now can have both i386 and amd64 libraries installed in parallel, which allows to replace foo:i386 with foo:amd64 without influencing the other parts of the system. The process is still full of pitfalls:
- In wheezy, many library packages are multiarch capable. This means that you can have those library packages installed for more than one architecture. This is a technical must for this way of crossgrade, so never use that for an older-than-wheezy system. It won't work, it needs at least Debian wheezy. Unfortunately, not all libraries in wheezy are multiarch capable. This makes the process harder and a lot less predictable, since a crosscrade including such packages is going to spew incomprehensible and misleading apt error messages. In my experience, for example the libaprutil-1-dbd-* packages and libonig2 are of this kind.
- apt removes a package before it reinstalls its new counterpart. This results in apt calling dpkg to remove dpkg, and then calling dpkg again to install dpkg. Guess which operation fails and the state of the system after this failure. Same applies to coreutils, which leaves the system without rm, which in turn dpkg of either architecture doesn't like. Using apt-get --download-only install to resolve dependencies and downloading the debs, followed by a traditional dpkg --install solves this issue since multiarch dpkg will replace a package with another one without deinstalling the first one first.
- At least for the process, you need a kernel that can run both 32bit and 64bit binaries for the i386 architecture. AFAIR, setting CONFIG_64BIT, CONFIG_X86_64 and CONFIG_IA32_EMULATION in the kernel configuration takes care of this.
- During the process, apt will temporary go into a badly broken state where it will refuse most operations. Be aware that you might need to manually download packages from the Internet. Be sure to have wget, curl, or a browser (maybe a text based one like elinks) available. dget is not going to help you here since it will only downloda packages for the native arch.
- During the process, apt wants to remove the better part of your system. It is important to not let it do this, as it wants to deinstall essential packages as well.
- Watch what your system does. During some steps, it might remove packages you might need. Keep track of the packages that were removed during the process and re-install them manually after finishing the crossgrade. Be sure not to purge packages that you might still need.
- It looks like the process is not always exactly reproducible. During the first tries, I found myself without an initrd at all, with an initrd that lacked the ext[234].ko kernel modules, without working e2fstools and in a number of other undesireable states of the system.
I have only tried this yet with a freshly installed minimal wheezy server system. Trying the process with "real life" systems has shown to be full of more surprises. I will document other pitfalls I have fallen into here at a later time. My minimal wheezy system was running in a KVM VM with its virtual disk as a LVM LV in the host system. I took a snapshot before beginning and used lvconvert --merge numerous time to return my LV to the original state. Be aware that lvconvert --merge removes the snapshot after merging it, so you'll need to re-create the snapshot before trying again.
The process is absolutely not for the faint of the heart, and intimate knowlegde of Debian mechanisms is required at many points in the process. Please seriously consider a reinstall+migrate approach instead of using this process, and be sure to practice it on a working copy of your system before touching the live system. And always have a backup.
During the process, I discussed things with Paul Tagliamonte, who has done this before, but on a live system and with a slightly more invasive approach. He has blogged about this. Thank you very much, your hints were very helpful.
Continue reading "How to amd64 an i386 Debian installation with multiarch"
In den letzten 24 Stunden habe ich endlich mal wieder was für Debian gemacht: dnstop und sipcalc vom bisherigen Maintainer übernommen, auf Vordermann gebracht und uploaded, und immerhin einen Alibi-Upload von pdns-recursor, damit auch der recursor mit der neuen Maintainer-Mailingliste im Maintainerfeld und dem korrekten Alioth-Vcs-Link im debian/control nach Wheezy kommt.
I have published PowerDNS version 3.1-1.0 on https://ivanova.notwork.de/~mh/debian/pdns/
This is a preliminary package and a release candidate to be 3.1-2 in Debian. If you're interested in PowerDNS on Debian, please test this package.
I plan to upload next week. This package will vanish from the web server once the package is visible in Debian.
Eight days ago, I uploaded atop 1.26-1 to DELAYED/8, listing me as new maintainer. This means that the package has in the mean time appeared in unstable, and I hope that it'll swiftly migrate to testing.
Alle Leute sagen, btrfs sei die Zukunft. Es gibt Leute, die einen schon mitleidig angucken, wenn man ihnen sagt, dass man immer noch ext4 einsetzt, wie ich das tue. Aber ich hatte neulich einen Grund, btrfs auszuprobieren. Mit btrfs kann man nämlich Snapshots innerhalb einer verschlüsselten LV einsetzen. Mit ext4 muss man vom Cryptodevice einen Snapshot machen und dann den Snapshot gesondert aufschließen. Damit ist schroot derzeit noch überfordert (#639105).
Also habe ich mal btrfs ausprobiert und musste feststellen, dass es mindestens beim Anlegen eines chroot massiv langsamer ist als ext4. Hier meine Messergebnisse für das Anlegen eines sid-chroot mit debootstrap mit und ohne eatmydata:
| fs | eatmydata | Laufzeit |
| ext4 | nein | 4:40 |
| ext4 | ja | 4:17 |
| btrfs | nein | 8:50 |
| btrfs | ja | 8:46 |
Ich muss sagen, ich bin entsetzt. Sowohl darüber, dass btrfs so viel langsamer ist, als auch darüber, dass eatmydata so gut wie nix bringt. Habe ich etwas falsch gemacht? Braucht btrfs beim Erstellen des Dateisystems bzw. beim Einhängen desselben irgend eine magische Option, um in die gleiche Performanceregion wie ext4 zu kommen?
Testumgebung war Debian GNU/Linux sid auf einer KVM VM.
Schon im neunten Eintrag in diesem Blog im Jahr 2005 ging es um munin. Es ist jetzt schon sieben Jahre her, dass ich dieses Tool einsetze. An vielen Stellen nervt es, aber die schlimmsten Macken sind mit der hoffentlich bald erscheinenden (aber auch als beta schon stabil laufenden) 2.0 abgestellt.
Munin 2.0 rechnet die Grafiken nur noch auf Anforderung neu, und mit einer noch mehr im Betastadium befindlichen weiteren Konfigurationsoption gehört auch munin-html der Vergangenheit an.
Bleibt nur noch das Problem, dass munin bei mehr als einer Handvoll Rechnern die Platte foltert. rrdtool rödelt auf den Datenfiles herum wie nichts gutes, und die Platte ist die ganze Zeit über beschäftigt. Auf die Dauer macht das keinen Spaß.
Mit rrdcached kann man die Datensicherheit gegen Geschwindigkeit oder geringere Systembelastung tauschen. munin 2.0 unterstützt rrdcached direkt, und nach wenigen Minuten Konfiguration und ein wenig Gefrickel mit den Permissions landen die fünfminütigen Updates nicht direkt im rrd-File, sondern erstmal im RAM des Munin-Masters. Der rrdcached schreibt die Daten dann auf Anforderung oder nach Ablauf einer bestimmten Zeit. Die Auswirkung des rrdcached sieht man hier: 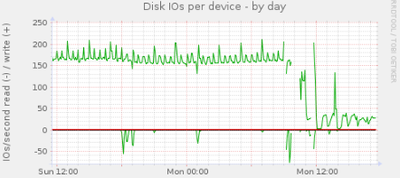
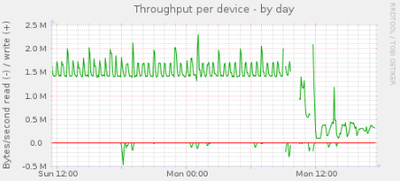
Die Bilder sprechen für sich.
Im Jahr 1999 habe ich im Rahmen meiner Diplomarbeit ein Framework entwickelt, das flexibel und leistungsfähig die Erstellung von - damals noch - ipfwadm-basierten Firewalls erlaubte. Irgendwann wurde es dann auf iptables aktualisiert und war insgesamt zwölf Jahre lang in zahlreichen Installationen im produktiven Betrieb.
Eben habe ich die letzten zwei Instanzen abgeschaltet. Und ich bin froh darüber.
Continue reading "letzte netfilter-init Installation ausser Betrieb"
From the perl DBI manual page:
If you'd like the cache to managed intelligently, you can tie the
hashref returned by "CachedKids" to an appropriate caching module,
such as Tie::Cache::LRU
And what happens when I don't do this? Will my cache be unintelligently managed then, with the consequence of my machine exploding when the cache is filled with more than a handful entries?
